
出征CES2019:盎锐科技用3D人工智能视觉技术,联结人与世界 原创
至顶网个人商用频道 01月19日 北京消息(文/黄当当):在智能手机“风向标”苹果的带动下,iPhone X用上了刷脸解锁的Face ID,一时间人脸识别成为AI在手机上最火的应用,3D视觉也顺势成为机器视觉赛道的一大风口。
这一趋势也蔓延至CES,在这个标志全球电子科技走向的舞台,你可能会诧异各种美妆品牌欧莱雅,SK-II,甚至美宝莲为何来参展,但你没有看错,在这些实时美妆,颜值检测的APP应用背后,正是3D视觉技术掀起的波澜。
就像建筑一幢高楼,人们在感概华丽外壳的同时,更应该注意到它打下的牢固地基。目前市面上基于3D视觉的应用千姿百态,而如何从“同质化”中获取独树一帜的体验,还得看核心功底,即背后的算法了。
盎锐科技就是这样一家公司,今年是他们第一次登上CES舞台,作为新生面孔,它却带来了3D视觉方面的一项独家专利,嗯,是CES舞台唯一的出现。
这个3D面部生成,跟别家还真不太一样
你想成为“吴彦祖”,还差几步?这一款App会用1-100%的可视化距离告诉你,所有的经历与变化,并且用3D任意拖拽的方式。
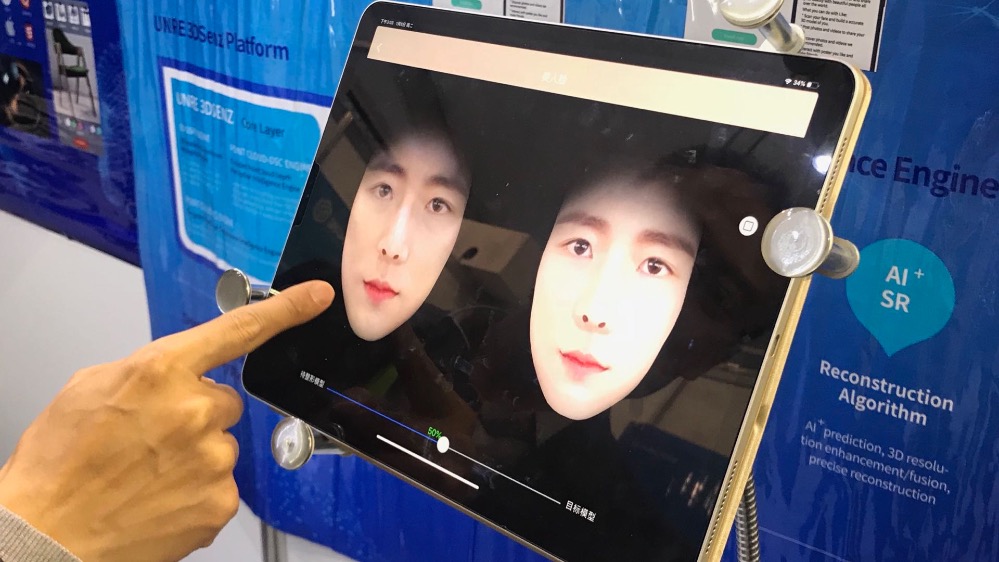
这是盎锐科技独家的算法。不出意料,这一应用受到美容医疗行业大赞,尤其是脸部的微调,可是方便美容医师与客户的沟通,以及调整方案的制定。

盎锐科技COO李辉表示,这项技术目前在大美医美行业非常受热捧,并且属于盎锐科技一家独有,是一项行业等待很久才出现的技术,同时医美行业也是盎锐科技3D人工智能视觉技术首先落地的领域,他表示,公司会先从医美行业开拓市场,进而继续向安防、教育等领域深耕。
那么,3D人工智能视觉技术与传统3D有何不同?李辉进一步解读,3D人工智能视觉技术是一种融合技术的概念,融合了AI、计算机视觉以及计算机图形学,以进行数字化真实的三维世界信息。
事实上,盎锐科技的目标是将3D人工智能视觉技术应用在所有需要将真实三维世界信息数字化的场景,比如人脸支付, 远程医疗, 全息视讯,空间建模,逆向工程建模等等。
用产品说话,让3D联结人与世界
“未来手机里的照片可能都是3D的,就像现在2D照片取代了黑白,这是一种进程。”李辉说道,未来社交App上的照片都会是3D方式呈现。
这或许与公司创始人的经历有关。盎锐科技创始人孙燕生,为3D智能视觉技术专家,创办了三家公司在纳斯达克上市(WEITEK、C-CUBE、DVS),被DVD Forum授予终身成就奖,被称为“MPEG之父”,是世界第一台VCD的主要发明人之一。
 盎锐科技创始人孙燕生博士做产品演示
盎锐科技创始人孙燕生博士做产品演示
对于图像的演进,盎锐科技这家公司认为未来将是3D的世界,为了让真实三维世界与数字化三维世界的融合更加自然,让实与虚之间切换更加快速,所以要让这个“虚”变得更高效,更简单,更真实,透过3D人工智能视觉技术的力量, 连接人与世界是盎锐研发3D人工智能视觉技术的愿景。
“其实,3D世界离我们并不远,或者说它已经到来。”李辉举了两个例子。
比如人脸支付,人脸相较于二维码,是更接近于真实的自己,然而,我们目前还停留在使用手机出示绑定自己个人信息的二维码进行支付,是极不符合人性的。而人脸支付的核心问题就是如何把真实三维世界的人像数字化提供给到机器,进行判定并核可一笔交易。
比如远程医疗或医疗美容,将真实三维世界的人像进行数字化处理,并且在数字化三维世界的人像处理结果最真实的对应到真实三维世界人像,这对手术模拟以及远程看诊都有极大的帮助。
不止算法,还有从软到硬的生态布局
作为一家Focus on3D视觉的初创公司,盎锐科技目前已实现3D视觉技术算法的成型,除了技术授权的商业模式,它还在做落地产品。
盎锐科技拥有自主研发的3D人工智能人像处理技术和4D人像视频直播技术, 并且已经推出可商用化的软件SDK, 软硬件解决方案, 以及嵌入式运算加速解决方案等产品可被广泛应用于医疗、安防、教育等领域。
在盎锐科技位于LVCC的展台,就展示了4D视频直播技术,不需要任何外挂特殊摄像头,使用带3D摄像头的iPad即可实现。
 3D人像数据压缩及加密技术演示
3D人像数据压缩及加密技术演示
当然,对于3D图片的处理,存储问题是一大考验,不过盎锐科技首席营销官李韦睿表示,盎锐科技已经研发出3D人像数据压缩及加密技术, 可以将3D人像进行1000倍压缩并且解压缩后可达到99%的解压缩无损率。
李辉表示,搭载盎锐的技术的产品,会出现在云端、嵌入式设备以及PC端,接下来还将与客户合作推出大美业智能3D人像处理及分析设备,智能家居3D人像处理及分析设备,嵌入式3D人像处理及分析移动终端,3D视频录制设备,高精度人像及人体扫描设备等等。
关于未来更广阔的布局,他表示,会考虑去做芯片,如果体量上来,会去在专属芯片上优化盎锐AI算法,并移植到现有设备端,不过这太长远了,眼下他更希望盎锐成为3D人工智能视觉技术领域的新独角兽级别的全球型企业。
好文章,需要你的鼓励



浙江大学团队破解AI图像生成大难题:让多个对象在同一张图里“听话站队“
浙江大学研究团队开发了ContextGen,这是首个能够同时精确控制多个对象位置和外观的AI图像生成系统。该系统通过情境布局锚定和身份一致性注意力两大创新机制,解决了传统AI在多对象场景中位置控制不准确和身份保持困难的问题,并创建了业界首个10万样本的专业训练数据集,在多项测试中超越现有技术。

Google发布Nano Banana Pro最新图像生成模型
谷歌推出升级版图像生成模型Nano Banana Pro,基于最新Gemini 3语言模型构建。新模型支持更高分辨率(2K/4K)、准确文本渲染、网络搜索功能,并提供专业级图像控制能力,包括摄像角度、场景光照、景深等。虽然质量更高但成本也相应增加,1080p图像费用为0.139美元。模型已集成到Gemini应用、NotebookLM等多个谷歌AI工具中,并通过API向开发者开放。

上海交通大学推出SR-Scientist:让AI像科学家一样自主发现数学规律
上海交通大学研究团队开发的SR-Scientist系统实现了人工智能在科学发现领域的重大突破。该系统能够像真正的科学家一样,从实验数据中自主发现数学公式,通过工具驱动的数据分析和长期优化机制,在四个科学领域的测试中比现有方法提高了6%-35%的精确度。这标志着AI从被动工具转变为主动科学发现者的重要里程碑。
2019
01/19
19:24
分享
点赞

智能体时代,IT决策者如何重塑测试体系:从资源消耗到价值引擎战略转型
具身智能大算力开发平台S600重磅亮相,地瓜机器人引领端云一体机器人进化新范式
联想刘军:中国区客户直营占比达到80%
联想基础设施业务增势强劲盈利基础稳固 第二财季营收近300亿元
枫清科技与麒麟软件达成战略合作,国产AI一体机亮相京津冀信创大会
一张“慢”榜单与一场“快”战争:中国算力排行榜的变与不变
昆仑元AI携手AMD重磅发布GPT-Factory Mini AI工作站
Google发布Nano Banana Pro最新图像生成模型
Gemini新增AI图像检测功能,但识别能力有限
ChatGPT全球推出群聊功能,支持多人协作对话
Google联手西屋推动核反应堆建设智能化优化方案
Sunday公司推出家用机器人Memo,计划让机器人走进千家万户
